はじめに
この本を手にとってくれたそこのあなた!はじめまして(あるいはお久しぶり!)本書の著者、nasa と申します。
まず、この本が生まれた背景をお話していきますね。本書はボクの「非同期処理の仕組みをなるべく隅から隅まで理解したい」という思いから生まれました。主に JavaScript を使う場面で、async/awaitを用いた非同期処理、非同期プログラミングをしています。しかし、その具体的な仕組みを知らないままで使っています。たとえば「アプリケーションサーバーにリクエストを投げる」という処理があったとします。このタスクはいつ実行されるのでしょうか?そして、実行のタイミングを誰が決めているのでしょうか? プログラマーである私でしょうか?
どのタスクをいつ実行するかを決めているのはランタイムと呼ばれるものになります。本書ではこのランタイムの実際のコードを読んでいくことで非同期処理、非同期プログラミングをより深く理解していこう、内部動作を理解することでより高みを目指そう!という本になります。
改めて本書を手にとってくれてありがとうございます!
想定する読者層
本書は、こんな人に向けて書いています。
- 「そもそも非同期処理とはなんぞや?」と思っている人
- 非同期処理は知っているけど、仕組みまでは知らない人
- 非同期処理ランタイムを読みたい人
- 非同期処理ランタイムを自作してみたい人
前提とする知識
本書では Rust の実際の非同期ランタイムを読み書きしていきます。なので、前提知識として次のものがあったほうが良いです。
- プログラミングの基礎的な知識
- Rust のコードが読める方
- Rust をはじめて読むけど、雰囲気は掴めるだろうという自信のある方
本書の特徴
本書は、非同期処理の解説、必要になった経緯から非同期ランタイムのコードリーディング、非同期ランタイムの実装を実際に著者である僕と一緒にやる本です。
大きく3部構成になっています
- 第 1 章: 非同期処理とは?
- 非同期処理をあまり書いたことがない人向けに Rust での非同期プログラミング(
async/await)の説明から「なぜ非同期処理が必要なのか」を解説する内容。
- 非同期処理をあまり書いたことがない人向けに Rust での非同期プログラミング(
- 第 2 章: ランタイムを読んでみよう
- Rust の非同期処理ランタイム
async-stdのランタイムを実際に読んでいく。
- Rust の非同期処理ランタイム
- 第 3 章: ランタイムを実装してみよう -> wip
第 1 章では、非同期処理というものが必要になったのか、その経緯とともに非同期処理の何が嬉しいのかを話していこうと思います。また、非同期処理を書いたことがないという方向けに Rust の非同期処理の書き方を少々、話していこうと思います。
第 2,3 章では実際にランタイムを読み書きしていきます。まず 2 章でランタイムのコードを実際に見ていき、全体像の理解、気をつけるべきポイントを見ていきましょう。ここで読んでいくコードは Rust の非同期処理ランタイムの 1 つであるasync-stdというライブラリの実際のコードです。
ここで一つ注意が必要なのですが、今回読むコードは master ブランチのものではなくnew-schedulerブランチのものを読んでいきます。new-schedulerブランチのランタイムを読む理由は、new-schedulerブランチのコードのほうが 1 つ 1 つのモジュールが疎結合になっており、コードが読みやすくなっているからです。また、ランタイムの動作が変更されたことやタスク実行方法がより効率的になっていることから、パフォーマンスも向上されています。(2020/02 時点での話)
そのため、new-schedulerブランチを読むほうが著者自身そして読者のみなさまの学びがあると判断しnew-schedulerブランチを読んでいくことにしました。
第 3 章では実際にラインタイムを実装していきます。ここで実装するランタイムはコードを非常にシンプルにすることを心がけます。しかし、余り使い物にならないものは作る気になれませんよね?なので、シンプルですが安全で高速に動作するランタイムの実装を目指します。
1 章で非同期処理を知り、2 章で理解を深め、3 章で理解を超深めていきましょう!
本書のゴール
本書を読み終わると、読者であるあなたは次のような状態になっているはずです。
- 自分ならではの非同期処理ランタイムを自作できるようになっている
- 非同期コードがどのような仕組みで動いているかの雰囲気がつかめる
問い合わせ先・フィードバック
本書は、著者である僕の学習も大きな目的となっています。まだまだこの分野は勉強不足です。なので、「こうした方が良いよ」、「ここ間違ってるよ」などの意見があると思います。
その場合は、次の GitHub リポジトリに issue を立てていただくか Twitter までご連絡下さい! 質問も大歓迎です。その場合は Twitter の方がレスポンスが早いと思います、気軽にご連絡下さい。
GitHub リンク: https://github.com/k-nasa/rust-async-book
Twitter id: @nasa_desu
謝辞
- TODO お世話になった方の名前を書く
執筆にあたってレビューをしてくださった皆さん本当にありがとうございました。他にもサークルメンバーの様々な方のサポートがなければ本書を書き上げることは出来ませんでした。本当にありがとうございました。その他、助言をくれた方々、本書関係者の方々に感謝します。
非同期処理とは
本章では、そもそも非同期処理とは何なのか、という話から始まり、Rust での非同期処理のコーディング方法について話していきます。そして、なぜ非同期処理が必要になったのか、非同期処理をすると何が嬉しいのかといった歴史を話していきます。最後に、非同期処理は並行処理の技法の一つですが、並行処理と並列処理は何が違うのかを話していきます。最後の並行処理と並列処理の違いは少し本筋から外れますが、コラムとしてお付き合いください。本章の内容をまとめると次の内容になります。
- そもそも非同期処理とは?
- なぜ非同期プログラミングが必要なのか?
- 並行処理、並列処理はどう違うのか?
内容を見て「全部だいたい知っている。なんとなく知っている」という人は 2 章まで読み飛ばしても大丈夫です。
非同期処理について
非同期処理とは?
多くのプログラミング言語はコードの実行の仕方として同期処理と非同期処理という分類があります。
同期処理
同期処理ではコードを順番に処理していき、ひとつの処理が終わるまでは次の行のコードを処理しません。書いた順番に動作するためとても直感的です。しかし、何かしらの大きな待ち時間を要する処理が行われていた場合、その待ち時間を要する処理が終わるまで、次の処理へ進むことが出来ません。次のコードを例に考えてみましょう。sleep関数は指定した時間だけ(今回は 1 秒)プログラムの動作をブロックします。なので、2つ目のprintlnが実行されるまでに1秒かかってしまいます。
#![allow(unused_variables)] fn main() { use std::{thread::sleep, time::Duration}; println!("開始"); sleep(Duration::from_secs(1)); println!("このコードが実行されるまで1秒ブロックされる") }
コード例ではsleep関数を使いましたが、通常は何かしらの重たい処理が入ると考えて下さい。その時、重たい処理が間にあると大きな待ちが生まれてしまいますね。
非同期処理
非同期処理はコードを順番に処理していくという部分は変わらないのですが、一つの処理が終わるのを待たずに次の処理を実行します。Rust のasync/awatを用いて非同期関数の例を示します。3つの非同期関数を考えてみましょう。関数のシグネチャから、「歌を歌う(sing_song 関数)」ためには前もって「歌を学ぶ(lern_song 関数)」必要があるとします。
#![allow(unused_variables)] fn main() { async fn lern_song() -> Song { // do something } async fn sing_song(song: Song) -> Song { // do something } async fn lern_song() { // do something } }
歌の学習、歌うこと、ダンスを行うコーディング方法の 1 つとしてはそれぞれを順番に実行していく事です
fn main() { let song = block_on(learn_song()); // block_onで非同期関数の完了を待つ block_on(sing_song(song)); block_on(dance()); }
この方法では1つのことを順番に実行しているだけなので、最高のパフォーマンスを実現しているわけではありません。明らかに、歌を学んだ後に「歌う」と「踊る」は同時に実行できますよね。
async fn learn_and_sing() { let song = learn_song().await; sing_song(song).await; } async fn async_main() { let f1 = learn_and_sing(); let f2 = dance(); // learn_and_singとdanceの完了を待つ futures::join!(f1, f2); } fn main() { block_on(async_main()); }
このように、同期処理のときとは違い、何かしらの重たい処理が入ったとしても、その大きな待ち時間の間にほかの処理を進められるのが非同期処理です。
なぜ非同期処理が必要なのか
それでは、なぜ非同期処理が重要になったのでしょうか?まずは歴史から入ってみましょう。
C10K 問題
「C10K 問題(クライアント 10,000 台問題)」とは一言でいうと、ハードウェアの性能上は問題がなくともクライアントの数があまりにも多くなると(およそ 10,000 台)レスポンス性能が大きく低下する問題です。これは、1 つの接続ごとに対応するプロセスやスレッドを割り当てるという方式では限界が来ているという問題です。
1つの接続ごとに対応するプロセスやスレッドを生成するとメモリ上にプロセスやスレッドの管理領域が確保されます。このとき、スレッドやプロセスを1つ起動するには数 KB ~ 数 MB のメモリが必要になります。そのため、同時に 10,000 ものアクセスがあると、数十 GB のメモリが必要になり、メモリが枯渇してしまいます。また、実行するプロセスやスレッドを切り替える際のコンテキストスイッチのオーバーヘッドが大きくなり、本来やるべき処理に時間が避けなくなってしまうという問題点もあります。
これを聞いて疑問が湧いた人がいるかも知れませんね。コンテキストスイッチのオーバーヘッドとは具体的に何か?次はコンテキストスイッチに掛かるコストについて話していきます。
コンテキストスイッチのオーバーヘッドとは具体的に何か?
CPU 上で処理中のデータを失う事なく現在のプロセスから別のプロセスに切り替えを行うには、現在のプロセスが使用しているレジスタなど CPU の状態を保存、復帰出来るようにする必要があります。この CPU の状態の事をコンテキスト、保存と復帰を行いコンテキストを切り替える事をコンテキストスイッチと呼びます。
プロセスのコンテキストスイッチ時のコストは次のものがあります。
- プロセスのすべての CPU レジスタのコンテキストを保存し、他のプロセスの値を復元する必要がある。
- CPU の仮想アドレスから物理アドレスのマッピングを切り替える必要がある。
- MMU キャッシュのクリア
「MMU キャッシュのクリア」について少し補足します。MMU というのはメモリ管理ユニット(Memory Management Unit)と言って、ハードウェアの一つです。CPU の要求するメモリアクセス処理するのが仕事になります。この MMU は仮想アドレスから物理アドレスへの変換の高速化のためにこれらの対応付けをキャッシュします。しかし、実行するプロセスを切り替える時は、仮想アドレスと物理アドレスのマッピングを切り替える必要がありましたね。このとき MMU キャッシュが残っていると、前に処理していたプロセスの領域を見てしまうことになります。
次はスレッドについて見ていきます。スレッドは、概念的にはプロセスと同じものですが、スレッドは 1 つのアドレス空間を共有します。そのため、プロセス切り替えのコンテキストスイッチ時のコストの一部が省略できます。プロセス切り替えの時は、現在の仮想アドレステーブルを次に実行するプロセスのものに切り替える必要がありましたが、スレッドの場合は、1 つのメモリ領域を共有しているため、仮想アドレステーブルの切り替えをする必要がありません。そのため、MMU キャッシュのクリアもする必要がありません。CPU レジスタの切り替え(コンテキストの保持と復元)は変わらず必要になります。しかし、メモリ領域を共有しているため、切り替えは「スタック領域」、「SP(スタックポインタ)」、「PC(プログラムカウンタ)」のみで済ませることが出来ます。 このため、プロセス切り替えに比べて、スレッドの切り替えはより素早く行うことが出来ます。しかし、スレッドのコンテキストスイッチは未だに高コストですし、多くの制限があります。
非同期処理で何が嬉しいのか
歴史についての長々しい話はここまでです! お疲れさまでした!1 つのタスクに1つのスレッド、プロセスを割り当てる方式では多くのリクエストは捌ききれないことが分かりましたね。この問題を回避するために、1 つのリクエスト、タスクに対して 1 つのプロセス、スレッドを割り当てるのではなく、スレッド数・プロセス数は固定のまま多くの処理を捌けるようにする必要があります。
スレッド数を固定するとどうなるか?
では、単純にスレッド数を固定してみるとどうなるでしょうか?次のコードを見てみましょう。
fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); let pool = ThreadPool::new(4); // スレッド数を4つに固定 for stream in listener.incoming() { let stream = stream.unwrap(); pool.execute(|| { handle_connection(stream); }); } } fn handle_connection(stream: TcpStream) { // do something }
このコードはリクエストごとにスレッドを起動するのではなく、スレッドプールを用いて処理しています。これによって指定したサイズ(このコードでは 4 つ)以上のスレッドが起動することはありません。4 つのスレッドのうち作業割当を待つスレッドに処理を割り当てることによってリクエストを捌いています。
このコードでは多くのリクエストを捌くことは可能でしょうか?
答えはhandle_connectionによりますが難しいでしょう。
handle_connectionが次のような処理だったとして考えてみましょう。ユーザーデータを問い合わせ、そのユーザーデータを使って外部 API への http リクエスト送信を行っています。
fn handle_connection(stream: TcpStream) {
let user = find_user() // DBへの問い合わせ。 500ms
send_http_request(user) // 外部apiへのリクエスト 500ms
}
この場合、1 つのリクエストを処理するには 1 秒かかってしまいます。そして、同時に処理できるリクエスト数はスレッドプールのサイズ分です。今回は 4 つなので1秒あたりに 4 リクエストしか捌けません。では、CPU 使用率はどうなっているでしょうか?やっている処理としては DB への問い合わせと外部 API へのリクエストです。なので、このサーバー自体ではほとんど処理を行っていないことが分かると思います。DB は外部にあると考えて下さい。
実行権限の移譲
先程のスレッドプールを用いた例から、ただ単にスレッド数を固定するだけだと CPU を有効に使えないことが分かりました。「外部 API へのリクエスト」といった時間がかかるが CPU を消費しない処理を実行したいときにコルーチンを利用することで、待ち時間の間に他の処理に実行権限を移すことが出来ます。
コルーチンとは
通常の関数は呼び出した後は最後まで処理を継続します。対して、コルーチンは呼び出した後に処理を途中で中断し、後から再開することが出来ます。
次の図を見るとそれぞれの違いがイメージできるかと思います。
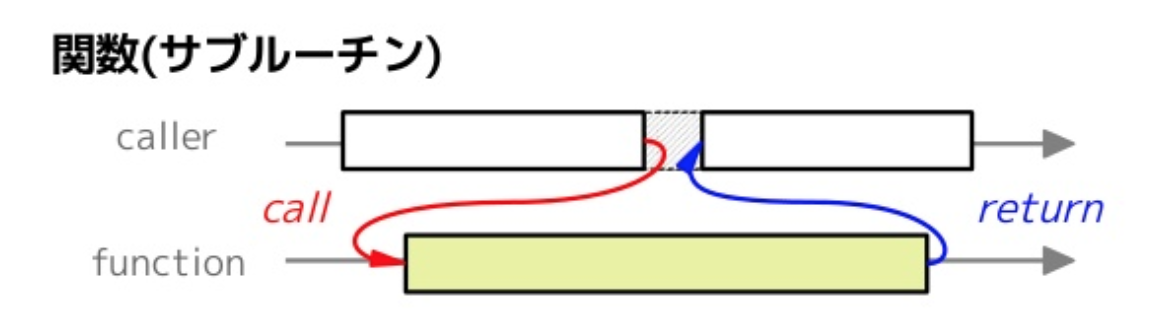
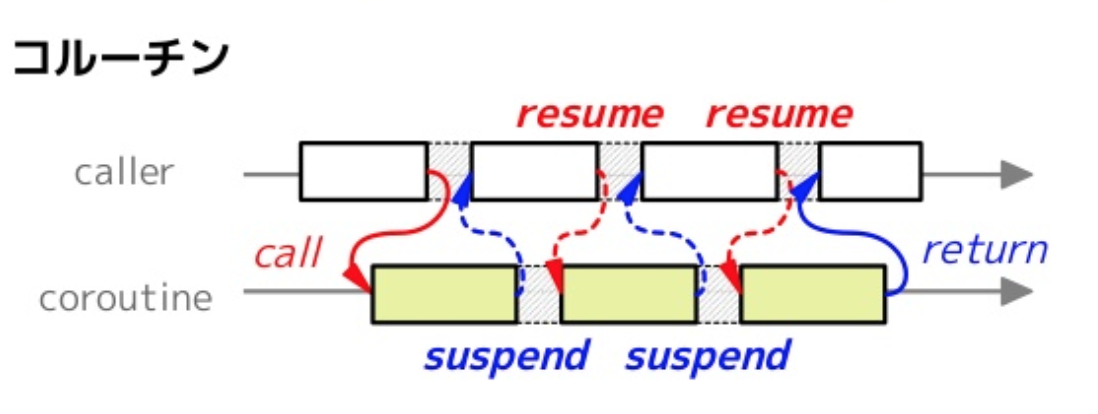
コルーチンの詳細は説明は本書では省きますが、コルーチンを利用、管理することで、タスクの「待機時間」があったときに、その時間は他のタスクに「実行権限を移譲」することでより効率的にタスクを実行することが出来ます。ちなみに先程見てきたasync/awaitは実はこのコルーチンを簡単に書くためのシンタックスシュガー(構文糖衣)です。
ここまでの説明で、非同期プログラミングをすることで並列または並行で実行できるコードを記述できることが分かったと思います。(分からなかったら、僕の説明が悪かったです。スミマセン orz)
今、「並列または並行」と言いましたが、並列性と並行性は何が異なるのでしょうか?この2つの用語はときどき意味を区別されずに使われています。並列性と並行性はどのように異なるのかをこれから話していきます。
並行性と並列性の違い
「Go 言語による並行処理」という本にこのような 1 文が出てきます。
並行性はコードの性質を指し、並列性は動作しているプログラムの性質を指します。
この 1 文はかなり分かりやすく、興味深い表現です。次のコードを実行するとします。このとき、async_main関数で2つの非同期関数hogeとfugaを「並列」に動作するように書いています。
#![allow(unused_variables)] fn main() { async fn hoge() { // do something } async fn fuga() { // do something } async fn async_main() { let f1 = hoge(); let f2 = fuga(); // hoge,fugaの完了を待つ futures::join!(f1, f2); } }
では、このコード(async_main関数)を実行したとき、hogeとfugaという2つの関数は並列に動作するという「保証」はあるのでしょうか?
マシンの CPU が1コアだったら何が起きるのでしょうか?並列に動作しますか?この時hogeとfugaは並列に動作しているように見えますが、実際は 2 つの処理を素早く切り替えながら逐次実行しています。つまり、hogeとfugaは並行に動作します。このコードを 2 コアのマシン上で実行するとhogeとfugaは実際に並列に動作するでしょう。つまり、私達は「並列に走って欲しい並行なコード」を書いていますが、実際のところはプログラムのランタイムが様々な抽象化を行い「並列に動作させてくれる可能性がある」ということです。(様々な抽象化とは、OS 自体の違い,OS が動作しているプラットフォームの違い、CPU の違いなどが当てはまります。)
もう一度良いまずが、並列性は動作しているプログラム(非同期ランタイム)の性質であって、コードの性質ではないのです。
ランタイムを読んで理解しよう
では、ついに実際の非同期ランタイムのコードをなるべく隅から隅まで解説していこうと思います。
今回読んでいくコードはasync-stdという Rust の非同期処理用ランタイムクレートです。このクレート(Rust ではライブラリのことをクレートと呼びます)はランタイムだけではなく、Rust の標準ライブラリ(std)を非同期にしたものでもあります。stdでは同期的だった File IO などを非同期化した関数群を提供するのがこのクレートの目的でもあります。本書ではランタイム部分しか触れませんが、一応これから読んでいくクレートの紹介を雑にしておこうと思いました。
注意事項ですが、今回読んでいくコードはasync-stdの master ブランチのものではなく、new-schedulerブランチのものになります。このブランチはまだ取り込まれていないため、本書で触れていくコードがasync-stdで今後使われていくか分かりません。現状、PR が出ている状態で、コードレビューや議論が行われている最中となっています。まえがきでもありましたが、再度new-schedulerブランチのコードを読んでいく理由を話します。new-schedulerブランチのランタイムを読む理由は、new-schedulerブランチのコードのほうが 1 つ 1 つのモジュールが疎結合になっており、コードが読みやすくなっているからです。また、ランタイムの動作が変更されたことやタスク実行方法がより効率的になっていることから、パフォーマンスも向上されています。そのため、new-schedulerブランチを読むほうが著者自身そして読者のみなさまの学びがあると判断しnew-schedulerブランチを読んでいくことにしました。(2020/02 時点での話)
それでは実際に非同期ランタイムを読んでいきましょう!
ランタイムがしていることって何だっけ?
ついさっき「読んでいきましょう!」と言っておいて申し訳ないですが、もう少し、お話をしましょう。ランタイム、ランタイムと言っていますが、これは裏で何をしてくれているのでしょうか?ランタイムは普段、私達が書いているコードには登場しません。秘密裏に私達の書いたコードを並行、または並列に動作させてくれます。これによって私達は簡単に、そして安全により効率的なプログラムを書くことが出来ています。 この縁の下の力持ちが本書の主役ですが、今の所、紹介もなければ、登場すらしていません。これで主役と言えるのでしょうか?なので、これからは「ランタイムくん」にスポットライトを当てていきます。
async-std を用いたコードを少し見ていこう
2020 年 2 月現在の Rust(1.41.0)では、1 章で出てきたasync/awaitなどを使い非同期関数や非同期ブロックで非同期タスクを作る事はできます。しかし、生成した非同期タスクを実行するすべは用意されていません。そのため、非同期タスクを正しく起動して実行を監視し、きちんと非同期タスクを完了させるために非同期ランタイムを用いる必要があります。
それでは、async-std(ランタイムの一つ)を使って非同期コードを書いていくとどの様になるのでしょうか?0 ~ 9 までを画面上に出力するコードを見てみましょう。詳細な構文はここでは知る必要がないですし、今後ランタイムの中身を読んでいくときも知る必要がないように心がけます。そのため、構文の説明などはすべて省略します。
use async_std::task; fn main() { let mut futures = vec![]; // ベクター初期化 for i in 0..10 { // クロージャを定義 let async_function = async move { println!("{}", i); }; // いま定義したクロージャを実行する非同期タスクを生成 + スケジューリングしている let handle = task::spawn(async_function); // 非同期タスクのハンドラーを待機リストに入れる futures.push(handle); } task::block_on(async { for f in futures { // 各々の非同期タスクの完了を待つ f.await } }); }
このコード中に出てきたtask::spawnによって非同期タスクを生成することが出来ます。次に、task::block_onですが、これは非同期タスクの生成をしたのちその結果が返るまで現在のスレッドをブロックします。なのでこのコードはspawnで「変数 i の値を出力する」という処理をする非同期タスクを生成し、その後block_onで「各々の非同期タスク完了を待つ」という非同期タスクを生成し完了を待つという動きをします。このコードを実行すると何が出力されるでしょうか?ちょっと予想してみて下さい。
僕の環境では次のようになりました。(きっともう一度実行すると結果は変わるでしょうが。)
0
3
1
4
2
5
9
7
6
8
この結果の順序には特に意味はありませんが、0 ~ 9 までが順番に出力されないこと意味があります。async-stdのランタイムでは非同期タスクは生成した順に実行されるわけではないということが分かりますね。
また質問なのですが、このコードは並列で動作すると思いますか?それとも複数タスクを逐次実行しているのでしょうか?
1 章でも話した内容とかぶってしまいますが、このコードは「並列に動作してして欲しい」と思い記述したコードですが、実際にはプログラムのランタイムが様々な抽象化を行い「並列に動作させてくれる可能性がある」コードです。なのでこのコードだけを見て並列で動くのかは判断できません。
では、以下のコードの実装を読んでいきます。
https://github.com/async-rs/async-std/tree/new-scheduler/src/rt/runtime.rs
ちなみにこのコードに関する議論はこの PR で行われています。
https://github.com/async-rs/async-std/pull/631
ここからは Rust のコードがゴリゴリ出てくるので、Rust をやったことがない人にとっては学習コストが上がってくるかと思います。ともに頑張りましょう!
主要なコンポーネントの基本構造
この節では主要なコンポーネントの基本構造を見ていきます。Runtime は主要な3つのコンポーネントを上手く組み合わせて非同期タスクをを実行するのが仕事になります。なので、最初にそれぞれのコンポーネントの基本的な構造や役割を説明していきます。これから説明していくコンポーネントはランタイムを含め次の 4 つです。
- Runtime
- Machine
- Processor
- Reactor
Runtime の基本構造
まずは、今回メインとなる Runtime 型の定義を見ていきます。
#![allow(unused_variables)] fn main() { pub struct Runtime { // リアクター。IOイベントのキューとして機能する // I/Oイベントにより非同期タスクの処理がブロックされた場合にこのリアクターに登録しておきます。 // そして、I/Oイベントが終了した時にブロックされた非同期タスクの処理を再開させます。 reactor: Reactor, // グローバルな非同期タスクのキュー // 非同期タスクが生成されるとこのグローバルタスクキューまたは、後述するProcessorのローカルタスクキューに入ります。 // キューの中身の型はRunnable injector: Injector<Runnable>, // 後述するProcessorのローカルキューからタスクをもらうためのハンドラー stealers: Vec<Stealer<Runnable>>, // スケジューラーの状態 sched: Mutex<Scheduler>, } }
Runtimeは次のものを持つことが分かります。
- グローバルな非同期タスクのキュー
- 各
Processorの持つローカルキューからタスクを盗むためのハンドラー(詳細は後述します!) - リアクター(I/O イベントのキュー)
- スケジューラーの状態
少し、定義時に出てきた型について見ていきましょう。これらはどのようなものなのでしょうか?
Injector
Runtime の定義にInjectorという型がありましたね。Injectorとはなんでしょうか?これは複数のスレッド間で共有できるキューです。実行待ちの非同期タスクを保持するために用いられます。実際にランタイムが非同期タスクが保持したり、取り出したりといった動作は後から見ていきましょう。
#![allow(unused_variables)] fn main() { // Injectorのコード例 // pushやstealで出し入れを行う use crossbeam_deque::{Injector, Steal}; let q = Injector::new(); q.push(1); q.push(2); assert_eq!(q.steal(), Steal::Success(1)); assert_eq!(q.steal(), Steal::Success(2)); assert_eq!(q.steal(), Steal::Empty); }
Runnable
タスクキューはRunnable型を保持します。ここではコードは簡略化しますがRunnable型はrunメソッドを持ち、これを実行することで非同期タスクを実際に動かすことが出来ます。
#![allow(unused_variables)] fn main() { pub struct Runnable(async_task::Task<Task>); impl Runnable { pub fn run(self) { // run task } } }
Stealer
次にStealerについて見ていきましょう。Stealerはキューそのものではなく、キューからタスクを取得するときのためのハンドラーです。
詳細はあとから見ていきますが、各プロセッサーが各々で実行待ちのタスクを保持するローカルキューを持っています。そして、自分のローカルキューからタスクをどんどん消費していきます。しかし、この時、自分のローカルキューからタスクが無くなったらどうなるでしょうか?(すべてのタスクを消費した勤勉なプロセッサーが居た場合ですね。) 他のプロセッサーがせこせこ働いているのに自分だけ休むわけには行きませんよね。実行可能なタスクを見つける方法の1つは Runtime が持つグローバルキューからタスクを貰い受けることですね。ではグローバルキューにタスクがない時はどうでしょうか? この時プロセッサーは他のプロセッサーの実行待ちのタスクを盗みます。 このときに別のプロセッサーからタスクを取得するためのハンドラーがStealerになります。
主な使い方としてはInjectorと変わりませんが一応コード例を紹介しておきます。
#![allow(unused_variables)] fn main() { use crossbeam_deque::{Steal, Worker}; let w = Worker::new_lifo(); //LIFOなキューを初期化 w.push(1); w.push(2); let s = w.stealer(); assert_eq!(s.steal(), Steal::Success(1)); assert_eq!(s.steal(), Steal::Success(2)); assert_eq!(s.steal(), Steal::Empty); }
Scheduler
これはスケジューラーの状態を持つ型です。次のような定義になっています。詳細はここでは考える必要はありませんが、後々のコードを読んでいくときにどのような状態を持っていくか知っておいたほうが良いので紹介します。
#![allow(unused_variables)] fn main() { // スケジューラーの状態 struct Scheduler { // リアクターに対して再開できる非同期タスクがあるのかを問い合わせるときにこのフラグがtrueになる。 polling: bool, progress: bool, //アイドル状態のプロセッサーリスト processors: Vec<Processor>, // 動作しているMachineリスト(Machineはスレッドのことだと思って差し支えない) machines: Vec<Arc<Machine>>, } }
次にRuntimeの定義で出てきた主要な 3 つのコンポーネントを見ていきます。
おさらいすると次の3つでしたね。
- Machine
- Processor
- Reactor
Machineから見てきましょう。
Machine の基本構造
#![allow(unused_variables)] fn main() { // プロセッサーで動作しているスレッド struct Machine { // プロセッサーを保持する。 // このMachineがアイドル状態の時に他のMachineがプロセッサーを奪う時がある processor: Spinlock<Option<Processor>>, // タスクを実行するたびにtrueがセットされる progress: AtomicBool, } }
OS スレッドに付き一つの Machine があります。これはスレッドが起動する時、停止するときも連動して、Machine の生成、破棄が行われます。つまり、OS スレッドの個数分の Machine オブジェクトを Runtime が管理しています。すこしprocessorの定義について見ていきましょう。processorはSpinlockという型でラップされたOption<Processor>です。 Processor というのはここでは実行権を持つか持たないかを表すものだと考えていいでしょう。Machine に Processor が割り当てられていないとき(つまり processor が None のとき)は Machine は非同期タスクの実行権を持ちません。ランタイムは実行開始時に、いくつかの Processor オブジェクトを持ちます。現状では Processor の数は cpu のコア数分です。この Processor オブジェクトを実行したい Machine に割り当てることによって、cpu のコア数より大幅に大きい数の Machine が走らないように数を制限しています。 Machine は OS スレッドにつき 1 つなので、cpu のコア数より大幅に大きい数の Machine が走らないということは、OS スレッドが多分に作られないということでもあります。
また、progress が false になっている Machine(動作中ではないスレッド)は Processor(実行権) を他の Machine に移譲します。この Processor の移譲処理はランタイムが行っています。
コラム スピンロック(Spinlock)とは
ここからはスピンロックの具体的な実装を見ていきますが、ランタイムの仕組みとは**ほとんど関係ありません!**なので、興味のない人は読み飛ばしても大丈夫です。この説の内容を知っていなくても本書は最後まで読み進められるように設計されているのでご安心を。
スピンロックは名前の通り、ロックの一種です。ロックが獲得できない間、単純に無限ループ(スピン)によってロックの獲得を待つような仕組みです。これは一種のビジーウェイト状態を発生させるため、ロック待ち時間が長くなると CPU を無駄に消費してしまう場合があります。
スピンロックの具体的な実装は次のようになってます(すこし簡略化しています。)
#![allow(unused_variables)] fn main() { pub struct Spinlock<T> { // ロックされていない(false) or ロックされている(true) // (余談ですが、flagというフィールド名ではなくlockedなどに変更したほうが分かりやすいのではないかと思います。) flag: AtomicBool, // 保持するデータ value: UnsafeCell<T>, } // Spinlockはスレッドセーフであると宣言する unsafe impl<T: Send> Send for Spinlock<T> {} unsafe impl<T: Send> Sync for Spinlock<T> {} impl<T> Spinlock<T> { // コンストラクタ pub const fn new(value: T) -> Spinlock<T> { Spinlock { flag: AtomicBool::new(false), value: UnsafeCell::new(value), } } // ロックを試みる pub fn lock(&self) -> SpinlockGuard<'_, T> { let backoff = Backoff::new(); // flagがtrueの場合(他によってロックされている場合)は無限にループを続ける // falseの時はflagにtrueをセットしてループから抜ける。 // 値の確認と値の変更は一気にやらないと競合状態が発生してしまう。 // そのため`swap`を使用している。 while self.flag.swap(true, Ordering::Acquire) { backoff.snooze(); } SpinlockGuard { parent: self } } } // ロックを保持するガード pub struct SpinlockGuard<'a, T> { parent: &'a Spinlock<T>, } // デストラクタ impl<'a, T> Drop for SpinlockGuard<'a, T> { fn drop(&mut self) { // ロックの開放時は単にflagをfalseにする。 self.parent.flag.store(false, Ordering::Release); } } impl<'a, T> Deref for SpinlockGuard<'a, T> { type Target = T; fn deref(&self) -> &T { unsafe { &*self.parent.value.get() } } } impl<'a, T> DerefMut for SpinlockGuard<'a, T> { fn deref_mut(&mut self) -> &mut T { unsafe { &mut *self.parent.value.get() } } } }
TODO Atomic 変数やメモリ順序についての説明を余裕があったら書く。
Processor の基本構造
それでは本題に戻りましょう。先程までに Machine の基本構造を見ていきましたね。次に Processor の基本構造を見ていきましょう。
#![allow(unused_variables)] fn main() { struct Processor { // ローカルタスクキュー worker: Worker<Runnable>, // 次に実行すべき非同期タスクを保持する slot: Option<Runnable>, } }
グローバルキューだけで非同期タスクを管理するようにしてしまうと、複数の Processor がグローバルキューから非同期タスクを取り出そうとしたときに競合状態が発生してしまいます。そのため、グローバルタスクキューからタスクを取り出す時は一度グローバルタスクキューをロックして他がタスクを取り出せないようにする必要があります。このグローバルタスクキューのロック取得をしなくて済むように各々の Processor が実行すべき非同期タスクをローカルタスクキューに保持していく形となっています。 また、ローカルキューをスキップする最適化として、slot に次に実行する非同期タスクを保持しています。slot に次のタスクを保持しておくことで、ローカルタスクキューやグローバルタスクキューへの毎回問い合わせをすることなくタスクを実行することが出来ます。
Reactor
Reactor は I/O イベントのキューとして作用します。I/O イベントキューとはなんのためにあるのでしょうか?次のようなコードを例に考えてみましょう。
#![allow(unused_variables)] fn main() { // udp socketをopen let socket = UdpSocket::bind("127.0.0.1:0").await?; // データ読込用のバッファを確保する let mut buf = vec![0; 1024]; // udp socketからデータを読み込む socket.recv_from(&mut buf).await?; // do something }
このコードでは udp socket からデータを読み込むまで次の行が実行されることはありません。それではいつになったら処理を再開することが出来るのでしょうか?upd パケットを受信した時このプログラムの動作を再開させることが出来るはずです。しかし、「upd パケットを受信した」というのはどうやって管理するのでしょうか?方法の一つとしては、この非同期タスクが継続可能かどうかを逐一問い合わせる方法があります。しかし、この方法では無駄な問い合わせが発生してしまい処理効率が良くありません。
そこで Reactor(I/O イベントのキュー)が使えます。この例だと、「upd パケットの読み込みイベント」を Reactor に登録しておきます。そして読み込み可能となったときにこの非同期タスクを再開可能として処理を再開させます。
ランタイムの起動と主な動作
ではここからランタイムの動作を見ていきましょう。最初に、ランタイムそのものはいつ起動しているのかを見ていきます。
そもそもランタイムはいくつも動作させるものではありませんよね?なので、最初に必要になったときだけランタイムを起動して、以後起動したランタイムを参照するようにしたいです。そういった用途では、once_cellというライブラリのLazyが使えます。次のコードはランタイムの定義です。
#![allow(unused_variables)] fn main() { use std::thread; use once_cell::sync::Lazy; // グローバルランタイム // 非同期タスクを登録するときなどに、ランタイムを参照する必要がある。 // この時はすべてこのRUNTIMEを参照することになる。 // このstatic変数RUNTIME以外にRuntimeが作られることはない。 pub static RUNTIME: Lazy<Runtime> = Lazy::new(|| { // ネイティブスレッドを一つ起動する。 // そしてそのスレッドではRUNTIME.run()を実行する。 // あとで実装を見ていくが、RUNTIME.run()は無限ループするのでこのスレッド上でランタイムは常に動作し続けることになる。 thread::Builder::new() .name("async-std/runtime".to_string()) .spawn(|| abort_on_panic(|| RUNTIME.run())) .expect("cannot start a runtime thread"); // 今後、RUNTIMEを参照した時はすべてこのオブジェクトを見ることになる。 // 先程のスレッドが起動されることはない。 Runtime::new() }); }
RUNTIME という static 変数を定義しています。この変数は最初に参照されたときに、Lazy::newの引数のクロージャが呼び出されます。つまり次の部分です。
#![allow(unused_variables)] fn main() { || { thread::Builder::new() .name("async-std/runtime".to_string()) .spawn(|| abort_on_panic(|| RUNTIME.run())) .expect("cannot start a runtime thread"); Runtime::new() //2度目以降の参照ではこのオブジェクトが参照される } }
そして、2度目以降の参照では RUNTIME は初期化時のクロージャの返り値として見られます。つまり、最初の参照では、ランタイムの動作用のスレッドが起動され、2度目以降の参照では動作している、Runtimeへの参照になるということです。Runtime への何かしらの処理(非同期タスクの登録など)はすべてこの RUNTIME 変数から行われるため複数のランタイムを起動してしまうこともありません。また、ランタイムは必要になるまで起動されないので、無駄にリソースを食いつぶすこともありません。
Runtime::new
では、起動時の非同期ランタイムの持つ情報は初期状態でどの様になっているのでしょうか?次のコードは Runtime のコンストラクタです。
#![allow(unused_variables)] fn main() { pub fn new() -> Runtime { let cpus = num_cpus::get().max(1); // cpuのコア数文だけ、Processorを生成する。 let processors: Vec<_> = (0..cpus).map(|_| Processor::new()).collect(); // 各々のProcessorが持つローカルタスクキューから非同期タスクを取得するためのハンドラーを作っておく。 let stealers = processors.iter().map(|p| p.worker.stealer()).collect(); Runtime { reactor: Reactor::new().unwrap(), // グローバルタスクキューは初期化時は空 injector: Injector::new(), stealers, sched: Mutex::new(Scheduler { processors, // 前節で紹介したとおり、Machineは非同期タスクを実行するために起動するOSスレッドの抽象化である。 // 初期化時点では実行すべき非同期タスクは1つもないため、実行用のスレッドを起動する必要もない。 // そのため、machinesは空のベクターでよい。 // あとから見ていきますが、このmachinesは既存のスレッド数では非同期タスクを処理しきれなくなったときに、その都度作られます。 machines: Vec::new(), progress: false, polling: false, }), } } }
次にランタイム用スレッドでは実際にどのような処理が行われているかを見ていきましょう。コードで言うとRUNTIME.run()の部分です。ここを見ていきましょう!
RUNTIME.run()
コードは多少簡略化していますが、次のようになっています。このコードは一気に読むには少し多いので、ポイントに絞って簡略化したコードをもとに説明していきます。小分けの説明をした後にこのコードに戻ってくるとスルスルっと理解できるはずです。
#![allow(unused_variables)] fn main() { pub fn run(&self) { scope(|s| { // スリープ時間のもとになるカウンター // ループの最後の方で使用している let mut idle = 0; // スリープする時間 let mut delay = 0; loop { // make_machinesは必要になるmachineのリストを返す for m in self.make_machines() { idle = 0; // カウンターを初期化 // 非同期タスク実行用のスレッドを1つ起動する s.builder() .name("async-std/machine".to_string()) .spawn(move |_| { abort_on_panic(|| { // Machine::runメソッドを呼び出す。 // 詳細な動作は後で見ていきましょう! m.run(self); }) }) .expect("cannot start a machine thread"); } if idle > 10 { // 10回以上何もせずにループしていた場合、 // 次のループ以降のスリープ時間を2倍ずつ増やしていく // このときに最大スリープ時間は10,000マイクロ秒としている(10ミリ秒) delay = (delay * 2).min(10_000); } else { // ループのたびにidelをインクリメントする idle += 1; // idelが10に満たないときはスリープ時間は一律で1,000マイクロ秒となる(1ミリ秒) delay = 1000; } // 指定されたマイクロ秒分だけスリープする thread::sleep(Duration::from_micros(delay)); } }) .unwrap(); } }
次のコードはランタイムの動作を一時的に止めるsleep処理のところのみを取り出しました。
#![allow(unused_variables)] fn main() { if idle > 10 { // 10回以上何もせずにループしていた場合、 // 次のループ以降のスリープ時間を2倍ずつ増やしていく // このときに最大スリープ時間は10,000マイクロ秒としている(10ミリ秒) delay = (delay * 2).min(10_000); } else { // ループのたびにidelをインクリメントする idle += 1; // idelが10に満たないときはスリープ時間は一律で1,000マイクロ秒となる(1ミリ秒) delay = 1000; } // 指定されたマイクロ秒分だけスリープする thread::sleep(Duration::from_micros(delay)); }
ランタイムは無限ループで動作しています。そして、新しく Machine を生成するべきかを毎回判断しています。そのため、新しく machine を作る必要がない状態が続いた場合 cup を無駄に消費し続けることになります。なので、毎回ループの最後にスリープ処理をはさみ、スリープ時間は何もしなかった回数(idel)に応じて増加していくという方式をとっています。
次に残りの部分を見ていきましょう。
#![allow(unused_variables)] fn main() { pub fn run(&self) { loop { // make_machinesは必要になるmachineのリストを返す for m in self.make_machines() { idle = 0; // idelカウンターを初期化 // 非同期タスク実行用のスレッドを1つ起動する s.builder() .name("async-std/machine".to_string()) .spawn(move |_| { abort_on_panic(|| { // Machine::runメソッドを呼び出す。 // 詳細な動作は後で見ていきましょう! m.run(self); }) }) .expect("cannot start a machine thread"); } // 先ほど説明したスリープ処理が入る } } }
まず、make_machinesで必要な個数分の machine のリスト返します。そして、その個数分の非同期タスク実行用のスレッドを起動します。その中で、実行すべき非同期タスクの見つけ、実行しています。
ここまでで、ランタイムの起動時の説明は以上です。
次からは必要になる machine 数を判定するmake_machinesと実際にタスクを処理していくMachine::runの動作を見ていきましょう。
make_machines
make_machines を呼び出すことで、必要なときに必要な文だけ Machine(os thread)を起動させることが出来ます。また、必要なくなった Machine が持っている processor(実行権限)を奪い、他の Machine に割り当てることで不必要にリソースを使わなくて済むようにしています。
#![allow(unused_variables)] fn main() { /// 起動すべきMachineのリストを返す関数 fn make_machines(&self) -> Vec<Arc<Machine>> { let mut sched = self.sched.lock().unwrap(); let mut to_start = Vec::new(); // 新しいMachineのリスト for m in &mut sched.machines { // 動作していないmachineからprocessorを奪う // この判定の時progressがtrueであってもfalseがセットされるため、 // 次にmake_machinesが呼び出されるとprocessorを奪われる可能性がある // ただし、machineは動作時に自身のprogressをtrueにするため、必ずprocessorを奪われるわけではない if !m.progress.swap(false, Ordering::SeqCst) { // processorにNoneをセットして、processorを奪う let opt_p = m.processor.try_lock().and_then(|mut p| p.take()); if let Some(p) = opt_p { // 奪ったprocessorを使用して新しいMachineを作る *m = Arc::new(Machine::new(p)); to_start.push(m.clone()); } } } if !sched.polling && !sched.progress { // processorリストから一つ取り出す // 取り出せない時(リストが空の時)は何もしない if let Some(p) = sched.processors.pop() { let m = Arc::new(Machine::new(p)); to_start.push(m.clone()); sched.machines.push(m); } sched.progress = false; } to_start } }
Machine::run (簡易版)
では今から async-std ランタイムの心臓部であるMachine::runのコードを呼んでいきます。コード行数としては 100 行を超えるため、最初は面を喰らうかもしれません。ただ一つ一つの処理では難しいことはしていません。初見では理解できなくても数回読んでみることで理解できるはずです。なので共に頑張って読んでいきましょう!
#![allow(unused_variables)] fn main() { fn run(&self, rt: &Runtime) { const YIELDS: u32 = 3; const SLEEPS: u32 = 10; let mut fails = 0; // タスクが見つからずに、何も実行しなかった回数 loop { // machineの状態を動作中に変更 self.progress.store(true, Ordering::SeqCst); // 実行すべき非同期タスクを探す // この時のタスクを探す順序としては次のようになっている // 1. このmachineの持つprocessorのローカルタスクキュー // 2. ランタイムの持つグローバルタスクキュー // 3. 他のprocessorのローカルタスクキューから盗む if let Steal::Success(task) = self.find_task(rt) { task.run(); fails = 0; // タスクを実行したので、何も実行しなかったカウントを初期化する continue; } fails += 1; // タスクを実行しなかった回数をインクリメント if fails <= YIELDS { // 連続で実行すべきタスクが見つからなかった回数がYIELDS未満の時 // このスレッドをしばらくの間実行しないことをOSスケジューラーに伝える thread::yield_now(); continue; } // 更に、連続でタスクが見つからなかった場合 // しばらくの間スリープします if fails <= YIELDS + SLEEPS { // 他のMachineにprocessorを盗まれないようにロックを保持 let opt_p = self.processor.lock().take(); thread::sleep(Duration::from_micros(10)); // 10μsスリープ *self.processor.lock() = opt_p; continue; } // 以下、更に連続でタスクが見つからなかった場合 let mut sched = rt.sched.lock().unwrap(); let m = match sched .machines .iter() .position(|elem| ptr::eq(&**elem, self)) // schedのmachineリストに現在実行しているmachineがあるか { None => break, // 無いなら、processorを盗まれているため、ループを終了してこのmachineに紐づくスレッドを閉じる Some(pos) => sched.machines.swap_remove(pos), }; sched.polling = true; drop(sched); // schedをdropすることによって取得したロックを解放している // reactorをpollしてI/Oイベントによってブロックされた非同期タスクが再開可能かどうかを問い合わせる。 // 引数としてtimeout時間を渡している。このときNoneを渡しているためtimeout時間は指定されていない // つまり、何かしらの非同期タスクが再開可能になるもしくは新しい非同期タスクが生成されるまでこのMachineの動作はブロックする。 rt.reactor.poll(None).unwrap(); sched = rt.sched.lock().unwrap(); sched.polling = false; sched.machines.push(m); sched.progress = true; fails = 0; } // ループ終了後の処理 // つまり、Machineに紐づくスレッドが閉じられるときの前処理を実行する let opt_p = self.processor.lock().take(); // このmachineの持つprocessorをschedulerのprocessorリストに戻す // その後、schedulerの持つmachineリストからこのMachineを削除する if let Some(p) = opt_p { let mut sched = rt.sched.lock().unwrap(); sched.processors.push(p); sched.machines.retain(|elem| !ptr::eq(&**elem, self)); } } }
ここまででランタイムの大まかな処理は終わりです。 長いことお疲れさまでした!
実際にランタイムを書いてみよう
TODO write
NOTE: async-rs/async-taskの中身を読んでいくのも面白そうなので、4章構成にしても良いかもしれない。